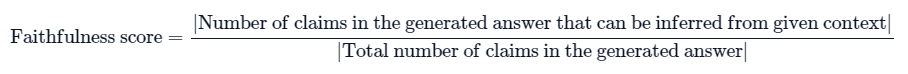
RAGAS(Retrieval-Augmented Generation Assessment System)是一個專門用來評估RAG(Retrieval-Augmented Generation)系統性能的工具,旨在提供全面和準確的測量,以幫助開發者和研究人員理解和改進RAG系統的表現。以下是RAGAS的詳細介紹:
RAGAS的設計目標是為RAG系統提供一個標準化的評估框架,這個框架可以有效地衡量系統在各個方面的表現,如回應的準確性、相關性、流暢性和語義相似度等。透過這樣的評估,開發者可以更好地調整和優化系統,從而提升用戶體驗和系統的實用性。
RAGAS提供了多樣化的功能,這些功能主要集中在以下幾個方面:
RAGAS支持從多個維度對RAG系統進行評估,每個維度都代表了RAG系統性能的不同方面:
語義相似度是RAGAS中的一個關鍵評估指標。RAGAS會計算生成的回答與標準答案之間的語義相似度,這通常通過語義嵌入技術來實現。例如,RAGAS可能會使用BERT或其他語言模型來將句子轉換為向量,然後計算這些向量之間的餘弦相似度。這種方法能夠比傳統的詞語匹配方法更好地捕捉到回答的語義內容。
RAGAS支持大規模的自動化評估,這意味著它可以處理大量的測試樣本,並生成詳細的評估報告。這一特性對於需要頻繁調整和測試RAG系統的開發者來說非常重要,因為它能夠顯著縮短測試時間並提高測試效率。
RAGAS設計為一個靈活且可配置的系統。用戶可以根據自身的需求自定義評估指標和權重,從而更好地適應不同應用場景的需求。例如,某些應用可能更加重視回答的精確性,而另一些應用則可能更關注回答的流暢性和語義相似度。RAGAS允許用戶根據這些需求進行配置,確保評估結果與實際需求一致。
RAGAS適用於各種涉及信息檢索和生成的應用場景,如:
RAGAS相較於傳統的評估方法,具有以下優勢:
隨著RAG技術的發展,RAGAS也將不斷更新和完善,以適應不斷變化的技術需求。未來的RAGAS可能會引入更多的智能評估功能,如自動錯誤分析、生成內容的情感分析等,進一步提升其評估的準確性和實用性。
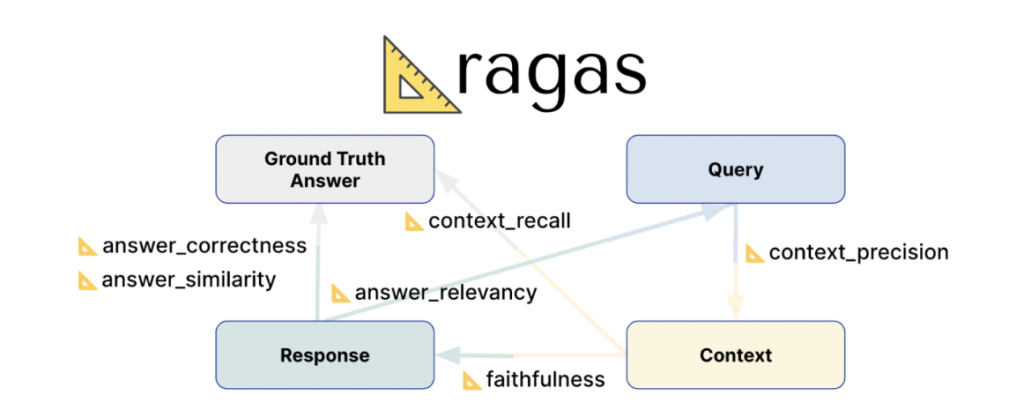
Ragas 提供許多評估指標供使用,可依照情境決定要套用哪個,這邊主要介紹此圖的六個指標
這邊來提供快速整理供記憶,細節就請各位去看一下官方文件啦
參考的檔案跟AI回應關,數值介於0~1之間,數值越高,代表回答得越好
from datasets import Dataset
from ragas.metrics import faithfulness
from ragas import evaluate
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[faithfulness])
score.to_pandas()
user query跟AI回應的關聯,較高的分數代表回答的相關程度很高
from datasets import Dataset
from ragas.metrics import answer_relevancy
from ragas import evaluate
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[answer_relevancy])
score.to_pandas()
user query跟參考的檔案是否相關
from datasets import Dataset
from ragas.metrics import context_precision
from ragas import evaluate
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[context_precision])
score.to_pandas()
正解跟參考檔案關係
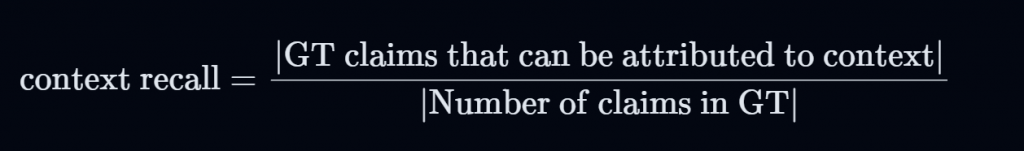
from datasets import Dataset
from ragas.metrics import context_recall
from ragas import evaluate
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[context_recall])
score.to_pandas()
AI回應跟正解關聯
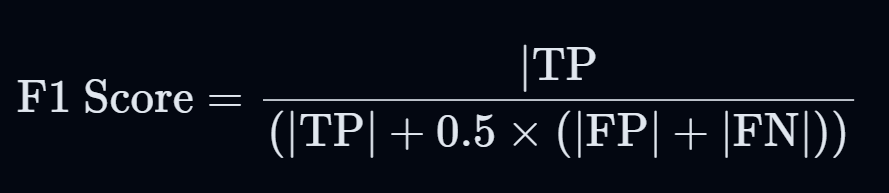
這邊是改良版的F1 Score,此公式的目的在於同時考慮TP、FP和FN,但在計算時給予了FP和FN較低的權重(0.5),可減少它們對最終F1 Score的影響。優點:
這種方法在一些特定情境下可能會提供更合理的評估,尤其是當我們希望對模型的錯誤寬容一些時
使用指定的嵌入模型將標準答案和生成答案向量化,然後計算這兩個向量之間的餘弦相似度
這兩個方面通過加權計算得到最終的Answer Correctness分數。用戶還可以使用“閾值”將結果四捨五入為二進制值(即正確或不正確)
from datasets import Dataset
from ragas.metrics import faithfulness, answer_correctness
from ragas import evaluate
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[answer_correctness])
score.to_pandas()
AI回應跟正解關聯
from datasets import Dataset
from ragas.metrics import answer_similarity
from ragas import evaluate
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[answer_similarity])
score.to_pandas()
最後,這邊提供整合多個評股指標的範例程式碼:
from datasets import Dataset
from ragas import evaluate
from langchain.schema import SystemMessage, HumanMessage
from ragas.metrics import (
context_precision,
answer_relevancy,
faithfulness,
context_recall,
answer_correctness
)
from ragas.metrics.critique import harmfulness
from ragas.run_config import RunConfig
questions = [
"問題1",
"問題2"
]
ground_truths = [
"正解1",
"正解2"
]
def summary_chain(query: str):
top_k = retrieve(query) # 回傳原始chunk的content
related_chunks = "\n\n".join([doc.page_content for doc in top_k])
messages = [
SystemMessage(content="你是一個非常了解銀行法規相關資訊的人"),
HumanMessage(content=f"請根據以下資訊回答我的問題:\n\n{related_chunks}\n\n 問題:{query}")
]
response = llm(messages=messages)
return {
"answer": response.content.strip(),
"context": top_k
}
data_samples = {
"question": [],
"answer": [],
"ground_truth": [],
"contexts": []
}
for question, ground_truth in zip(questions, ground_truths):
result = summary_chain(question)
print('result:', result)
contexts = [doc.page_content for doc in result['context']]
print('contexts:', contexts)
print(len(contexts))
data_samples["question"].append(question)
data_samples["answer"].append(result['answer'])
data_samples["ground_truth"].append(ground_truth)
data_samples["contexts"].append(contexts)
dataset = Dataset.from_dict(data_samples)
print('dataset:', dataset)
metrics = [
faithfulness,
answer_relevancy,
context_recall,
context_precision,
harmfulness,
answer_correctness
]
evaluation_result = evaluate(
dataset=dataset,
metrics=metrics,
llm=critic_llm,
embeddings=aoai_embeddings,
run_config=RunConfig(max_workers=4,max_wait=180,log_tenacity=True,max_retries=3)
)
print(evaluation_result)
以上就是Ragas 評測的介紹!